Neuroscience, neural nets, and nonequilibrium stat mech
About the lab
We are the lab of Michael DeWeese at UC Berkeley. Our interests fall into three rough categories:
Selected recent work
See here for a complete list.
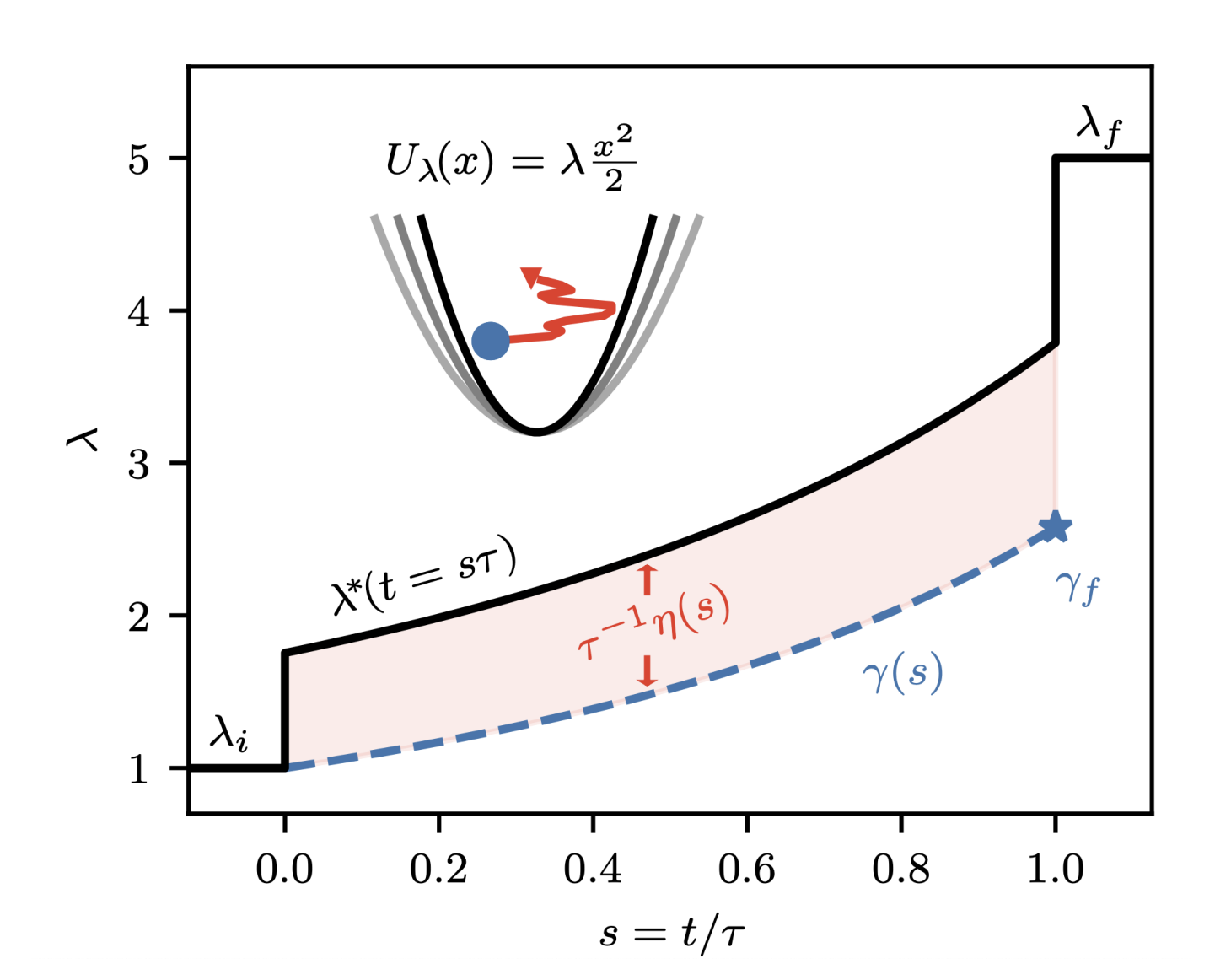
Equivalence between thermodynamic geometry and optimal transport
Thermodynamic geometry geodesics are optimal transport solutions
For a controllable thermodynamic system, what is the work-minimizing protocol transitioning between two states? It is known that if the transition is allowed to be slow, then the optimal protocol is a geodesic of the "thermodynamic geometry" induced by the Riemannian friction tensor defined on control parameters. We demonstrate that thermodynamic geometry--previously thought of as an approximate, linear response framework--is actually equivalent to optimal transport. From this equivalence, we show that optimal protocols beyond the slow-driving regime may be obtained by including an additional counterdiabatic term, which can be computed from the Fisher information geometry. Not only are geodesic-counterdiabatic optimal protocols computationally tractable to construct, but they also explain the intriguing discontinuities and non-monotonicity that have been observed before in optimal, work-minimizing protocols.
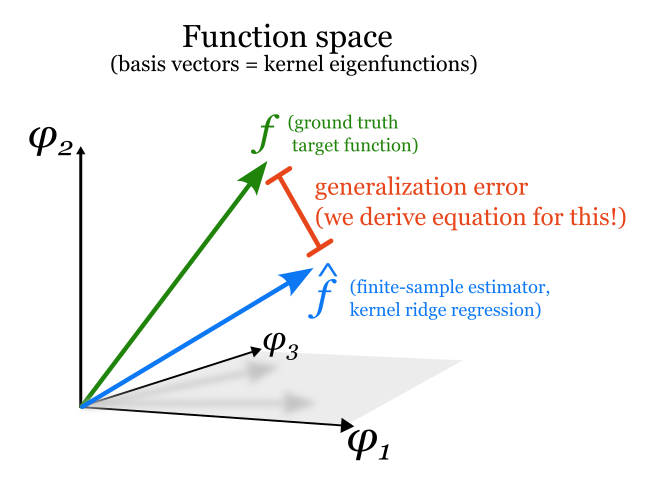
The Eigenlearning Framework
The eigensystem of a kernel predicts its generalization capabilities
The ability of neural networks to generalize without overfitting, despite having far more fittable parameters than training data, remains an open question. In this paper we derive equations that fully explain the generalization ability of a certain kind of neural network: very wide networks with suitably small learning rates. When trained, such networks are equivalent to kernel ridge regression. Our equations derive from the kernel's eigenvalues and the eigencoefficients of the target function; together, this eigenstructure captures all the salient properties of the network architecture, the data distribution, and the target function. In particular, the central object in our equations is a scalar we call learnability, which accounts for the kernel eigenstructure, the quantity of training data, and the ridge regularization strength. We find that the learnability of a target function is tractable to estimate, and our framework provides a theoretical explanation for the "deep bootstrap" phenomenon described by Nakkiran et al (2020), representing a major advance in understanding generalization in overparameterized neural networks.
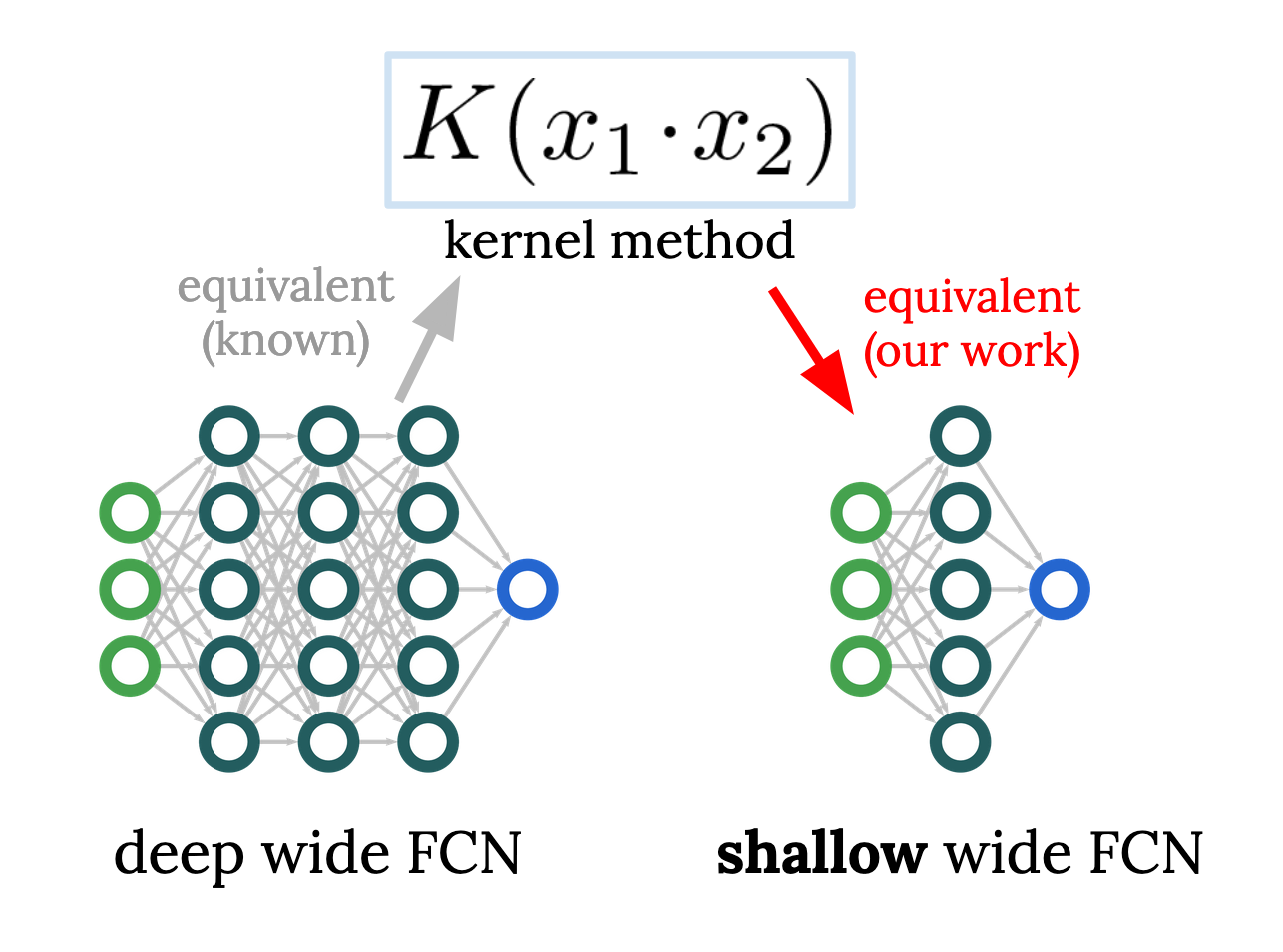
Reverse engineering the neural tangent kernel
A first-principles method for the design of fully-connected architectures
Much of our understanding of artificial neural networks stems from the fact that, in the infinite-width limit, they turn out to be equivalent to a class of simple models called kernel regression. Given a wide network architecture, it's well-known how to find the equivalent kernel method, allowing us to study popular models in the infinite-width limit. We invert this mapping for fully-connected nets (FCNs), allowing one to start from a desired rotation-invariant kernel and design a network (i.e. choose an activation function) to achieve it. Remarkably, achieving any such kernel requires only one hidden layer, raising questions about conventional wisdom on the benefits of depth. This allows surprising experiments, like designing a 1HL FCN that trains and generalizes like a deep ReLU FCN. This ability to design nets with desired kernels is a step towards deriving good net architectures from first principles, a longtime dream of the field of machine learning.
Redwood Center and Physics at UC Berkeley